Imbalanced datasets occur when one target class significantly outnumbers another in your training data. Consequently, machine learning models often ignore the minority class and simply predict the majority class to achieve high accuracy. SMOTE (Synthetic Minority Over-sampling Technique) solves this problem directly by generating synthetic, highly realistic examples of the minority class. Therefore, mastering SMOTE allows your models to learn true decision boundaries and make accurate real-world predictions.
During a rigorous data science screening interview, evaluators actively test your ability to handle severe class imbalance. Furthermore, in highly competitive predictive modeling environments, mastering advanced resampling often separates the top-tier experts from the rest. Consequently, understanding the deep mathematical mechanics of these techniques is strictly essential for practical success.
In this comprehensive guide, we will explore exactly how SMOTE functions under the hood. Specifically, we will cover the step-by-step implementation, advanced variations, and real-world applications. Additionally, we will examine the critical pitfalls that ruin otherwise perfect models.
The Danger of the Accuracy Paradox
Historically, many developers evaluate their models using standard accuracy metrics. However, relying on pure accuracy is highly deceptive when dealing with skewed data. For instance, if you have a dataset with 99 legitimate transactions and 1 fraudulent transaction, a broken model can achieve 99% accuracy by simply labeling everything as legitimate.
Consequently, this model is completely useless for its intended purpose. The algorithm has learned absolutely nothing about the minority class. Therefore, we call this phenomenon the accuracy paradox, and it routinely destroys predictive pipelines in production.
Moreover, failing to identify the minority class carries massive financial and ethical costs. According to the Nilson Report, global card fraud losses consistently exceed tens of billions of dollars annually. Thus, financial institutions must build models that prioritize minority class detection over baseline accuracy.
Understanding the SMOTE Algorithm
Data scientists developed SMOTE to overcome the severe limitations of random oversampling. Specifically, random oversampling simply duplicates existing minority data points. Consequently, this simple duplication often forces the model to memorize the data, leading directly to massive overfitting.
Instead of duplicating data, SMOTE interpolates new data points. The algorithm selects a minority class instance and identifies its k-nearest neighbors in the feature space. Subsequently, it draws an imaginary line between the original point and one of its neighbors.
Finally, the algorithm randomly places a synthetic data point along that connecting line. Therefore, the model expands the decision region of the minority class smoothly. To understand the underlying math, we use a specific vector calculation.
The algorithm generates the synthetic data point using the following formal equation:
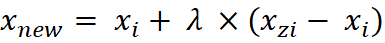
In this equation, lambda represents a random number strictly between 0 and 1. Consequently, this ensures the new point always falls exactly on the line segment connecting the two existing points. Therefore, the synthetic data is mathematically plausible and highly useful.
Step 1: Analyzing the Initial Distribution
Before you deploy any algorithm, you must first completely understand your data. Specifically, you need to measure the exact severity of the class imbalance. Therefore, robust exploratory data analysis is always your mandatory first step.
You must utilize comprehensive Data Analytics infrastructure to visualize these target distributions. If your ratio is 60:40, you might not need synthetic sampling at all. However, if your ratio is 99:1, intervention is strictly required.
Furthermore, you must establish baseline evaluation metrics that actually matter. You should immediately abandon standard accuracy. Instead, you must calculate precision, recall, and the F1-score for your baseline model.
Step 2: Implementing Proper Cross Validation
The most destructive mistake a data scientist can make is applying SMOTE to their entire dataset. Specifically, you must never synthesize data before splitting your data into training and testing sets. If you do this, data leakage will immediately occur.
When you oversample before splitting, synthetic points generated from the test set bleed into the training set. Consequently, your model will evaluate itself on data it has effectively already seen. Therefore, your validation scores will look incredible, but the model will fail instantly in production.
To prevent this, you must strictly perform oversampling inside your cross-validation loop. You must only ever apply SMOTE to the training fold during each iteration. Utilizing libraries like the Imbalanced-Learn API ensures your pipeline handles this isolation automatically.
Step 3: Applying SMOTE to the Training Data
Once your cross-validation loop is secure, you can instantiate the SMOTE algorithm. Specifically, you must define the k-neighbors parameter carefully. Typically, the default value of five neighbors works exceptionally well for most standard datasets.
However, if your minority class is extremely sparse, you might need to reduce this number. Conversely, increasing the neighbors creates a more generalized, smoother decision boundary. Therefore, you should treat the neighbor count as a highly tunable hyperparameter.
Furthermore, you must fit the algorithm strictly to your isolated training features and training labels. Once fitted, the algorithm outputs a perfectly balanced array of features and labels. Consequently, you can now feed this newly balanced data into your primary predictive model.
Step 4: Evaluating the Model Correctly
After training your model on the balanced data, you must evaluate it strictly on the untouched test set. Specifically, you must use metrics that heavily penalize minority class errors. The precision-recall area under the curve (PR-AUC) is highly effective for this task.
Unlike the standard ROC-AUC, the PR-AUC does not reward the model for correctly predicting the massive majority class. Instead, it focuses entirely on how well the model identifies the rare events. Therefore, it provides a strictly honest assessment of your model’s true capability.
Additionally, you should carefully analyze the confusion matrix. You want to see a massive reduction in false negatives compared to your baseline model. Consequently, this proves that the synthetic data successfully forced the model to recognize the minority patterns.
Summary Table Resampling Methods
To clarify exactly when to use specific techniques, review the technical comparison below. Consequently, this table helps you select the right architectural approach for your specific data.
| Resampling Technique | Technical Description | Primary Use Case | Critical Risk |
| Random Undersampling | Deletes majority class instances randomly | Massive datasets requiring faster compute times | Destroys potentially valuable majority class data |
| Random Oversampling | Duplicates minority class instances directly | Very small datasets with extreme scarcity | Frequently causes severe model overfitting |
| SMOTE | Generates synthetic minority instances via interpolation | Continuous feature sets needing defined boundaries | Can generate noisy points if classes heavily overlap |
| ADASYN | Generates more synthetic data near hard-to-learn examples | Highly complex datasets with erratic decision boundaries | Can over-focus on extreme outliers or noise |
Advanced Variations of SMOTE
The original SMOTE algorithm is highly effective, but it has specific geometric limitations. For instance, it can blindly generate synthetic points deep inside the majority class space if outliers exist. Therefore, researchers developed advanced variations to solve these edge cases.
Borderline SMOTE
This variation focuses entirely on the decision boundary between the classes. Specifically, it only selects minority points that are physically close to majority points. Consequently, it generates synthetic data exactly where the model needs the most help separating the classes.
SVMSMOTE
This technique uses a Support Vector Machine to find the initial decision boundary. Subsequently, it generates synthetic points specifically along that calculated hyper-plane. Therefore, it is highly effective when dealing with extremely high-dimensional datasets.
SMOTE NC
The standard algorithm completely fails if your dataset contains categorical text features. To solve this, SMOTE-NC (Nominal and Continuous) handles mixed data types perfectly. If you are processing complex text records, integrating Natural Language Processing alongside SMOTE-NC yields superior results.
Cost Sensitive Learning Alternatives
While synthetic generation is highly popular, it is not the only valid approach. Alternatively, you can modify the learning algorithm itself without touching the data. We call this approach cost-sensitive learning.
Specifically, you assign a massive mathematical penalty to the model whenever it misclassifies a minority instance. For example, in a tree-based model, you can adjust the class weights internally. Consequently, the algorithm naturally pays more attention to the minority class during gradient descent.
Furthermore, combining cost-sensitive weights with SMOTE often produces the absolute highest predictive accuracy. Building these hybrid architectures requires significant expertise. Therefore, engaging Custom AI Development specialists ensures your models remain highly stable and perfectly calibrated.
Integrating SMOTE with Machine Learning Models
Different algorithms react very differently to synthetic data. For instance, linear models like Logistic Regression benefit massively from the clear boundaries SMOTE creates. Consequently, their internal coefficients stabilize significantly after balancing.
Conversely, complex tree ensembles like XGBoost or Random Forest are already highly robust. However, feeding them SMOTE-balanced data prevents them from pruning vital minority class branches prematurely. Therefore, even advanced gradient boosting machines require proper data balancing.
When working with deep neural networks, balancing becomes strictly mandatory. Neural networks learn via mini-batches, and imbalanced data means many batches contain zero minority examples. By utilizing balanced data, you ensure consistent gradient updates across all your Machine Learning architectures.
Real World Case Study Medical Diagnostics
Let us examine a highly critical application of these techniques in healthcare. According to the World Health Organization, early detection of rare diseases drastically improves patient survival rates. However, medical datasets are notoriously imbalanced, often featuring thousands of healthy scans for every single malignant scan.
A leading medical research institute attempted to train a predictive model on raw, imbalanced data. Consequently, their initial model achieved 98% overall accuracy but missed 85% of the actual malignant cases. Therefore, the model was medically useless and highly dangerous.
By properly implementing SMOTE alongside deep convolutional networks, the engineering team completely transformed the results. Specifically, the synthetic generation allowed the model to learn the subtle geometric patterns of the rare tumors. As a result, the minority class detection rate improved by over 60%, directly saving lives.
Real World Case Study Financial Fraud
Similarly, the banking sector relies heavily on accurate anomaly detection. Credit card fraud represents a fraction of a percent of total daily transaction volume. Therefore, legacy rule-based systems constantly generate false positives, frustrating legitimate customers.
A major fintech company deployed an advanced gradient boosting model utilizing Borderline-SMOTE. Consequently, they trained the algorithm specifically on the difficult transactions hovering near the decision boundary. Furthermore, they continuously updated the data pipelines to prevent concept drift.
The results were financially staggering for the institution. By identifying the true minority patterns accurately, they reduced false positive declines by 40%. Additionally, they successfully caught 25% more actual fraud attempts, saving millions in operational chargebacks.
Common Pitfalls and Dimensionality Issues
Despite its immense power, SMOTE is not a magical solution for bad data. Specifically, if your features contain no actual predictive signal, generating synthetic noise will not help. Therefore, feature engineering remains your highest priority.
Moreover, extreme high dimensionality can severely cripple the distance calculations used by SMOTE. In spaces with thousands of features, the concept of “nearest neighbors” breaks down mathematically. Consequently, you must apply dimensionality reduction techniques like PCA before generating synthetic points.
Finally, handling images requires entirely different techniques. SMOTE cannot interpolate pixels effectively to create a new image. If you are building visual models, you must use strict data augmentation or Computer Vision specific generative models instead.
The Ethical Responsibility of Balanced Data
As AI engineers, we hold a profound ethical responsibility over the systems we build. When we ignore imbalanced data, we often silently discriminate against underrepresented groups. Consequently, an imbalanced algorithm simply automates and scales existing human biases.
For instance, if a loan approval model learns from skewed historical data, it will systematically deny minority applicants. Therefore, utilizing techniques to balance representation is not just a statistical requirement; it is a moral imperative. We must force our algorithms to recognize everyone equally.
By meticulously ensuring fair representation in your training data, you align your work with the highest professional standards. Ultimately, building honest, equitable technology is the only sustainable way to operate in the modern data ecosystem.
Actionable Next Steps
Are you ready to fix the predictive bias in your current machine learning pipelines? You can immediately improve your models by executing these three specific actions today.
- Audit Your Confusion Matrices: Stop looking at overall accuracy scores immediately. Check your existing models specifically for high false-negative rates in the minority class to identify hidden failures.
- Isolate Your Validation Folds: Review your training code and ensure you split your data before applying any resampling techniques. Strictly eliminate any data leakage from your cross-validation loops.
- Deploy a Baseline SMOTE Test: Implement the basic SMOTE algorithm on your training data using Python and compare the new PR-AUC score against your original imbalanced baseline.
Conclusion
Handling imbalanced datasets requires rigorous mathematical discipline and strict pipeline isolation. By utilizing SMOTE, you force your algorithms to learn the truth about your data, rather than taking the easy way out. Consequently, you will build highly robust systems that perform exceptionally well in the chaotic real world.
If you need custom architectural help implementing these advanced data pipelines, our AI Consulting & Strategy experts at Tensour are ready to assist. We specialize in building honest, fair, and highly accurate predictive systems. Reach out to us today to optimize your machine learning models at https://tensour.com/contact.
Leave a Reply