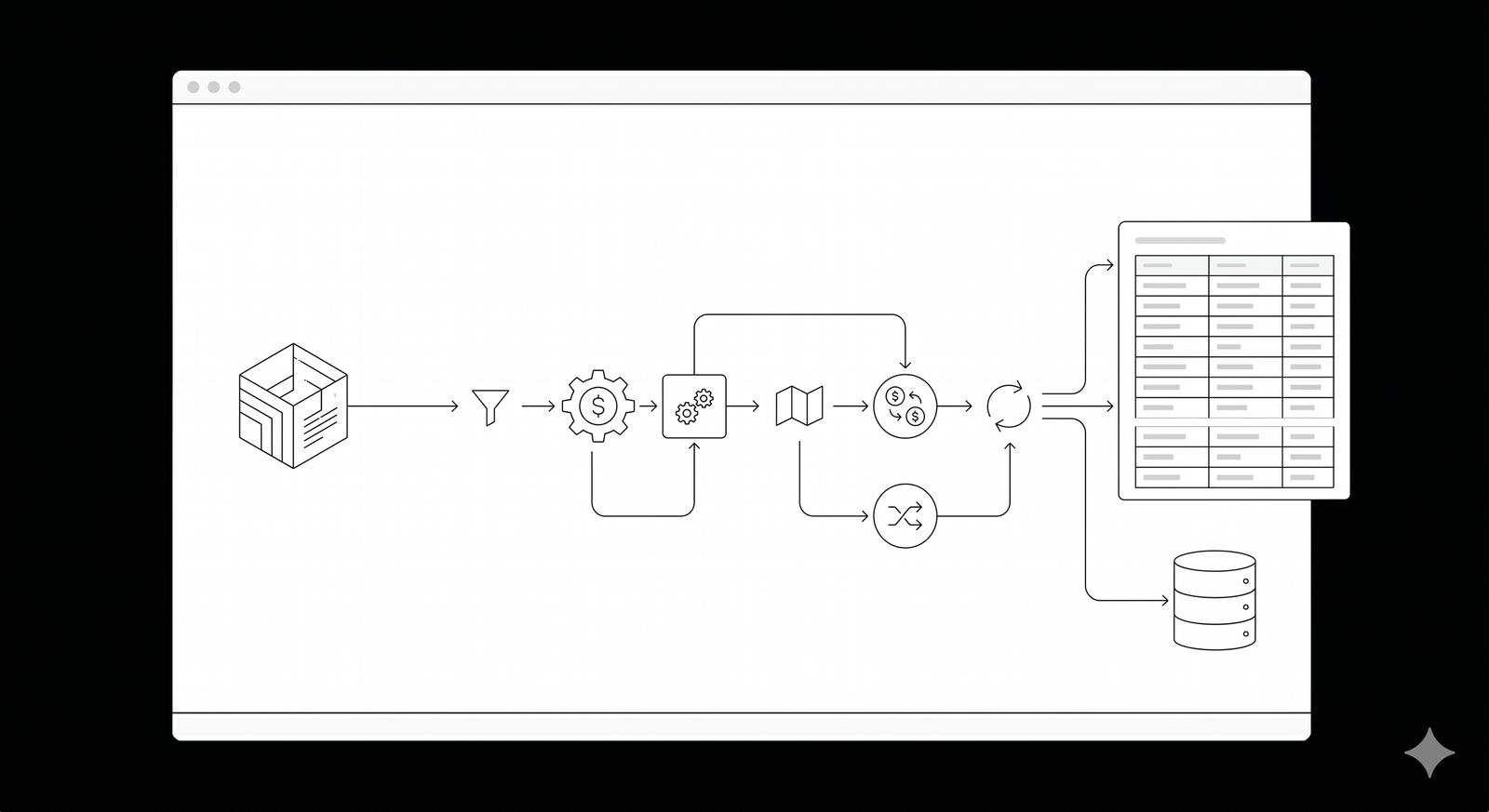
Financial data vectorization for Retrieval-Augmented Generation (RAG) is the precise technical process of converting dense financial documents into numerical arrays, or embeddings, so artificial intelligence can accurately search them. Accordingly, by utilizing structural chunking and domain-specific embedding models, developers ensure large language models retrieve exact numerical facts instead of hallucinating. Consequently, you can transform complex SEC filings and earnings reports into highly queryable, completely reliable enterprise knowledge bases.
Why Standard Vectorization Fails in Financial Markets
Standard vector databases simply split text arbitrarily and match keywords, which completely destroys the logical structure of a financial report. Therefore, when an analyst asks a question about Q3 revenue, a basic RAG system often pulls numbers from the wrong year or the wrong company. According to a recent benchmark study published on arXiv, traditional chunk-based retrieval suffers heavily from cross-document confusion when analyzing structurally homogeneous corpora like regulatory filings.
Furthermore, financial documents contain massive tables, strict legal jargon, and critical footnotes that must remain connected to their parent sections. Consequently, if you destroy this context during the embedding phase, your artificial intelligence will confidently provide wrong answers. Indeed, research from Snowflake demonstrates that without specialized RAG architecture, even powerful models score a dismal 5% to 10% accuracy on financial query benchmarks.
However, properly optimized retrieval pipelines dramatically change these outcomes. In fact, applying the right machine learning chunking strategies allows smaller, more efficient models to jump to over 70% accuracy. Because accuracy directly impacts financial trading and compliance decisions, you must engineer your data ingestion perfectly from the very beginning.
Step 1 Implement Structural and Markdown-Aware Chunking
Before you can embed text into a vector database, you must first split your raw documents into smaller pieces called chunks. Currently, most developers use simple recursive chunking, which cuts text after a fixed number of tokens. However, this naive approach frequently slices right through the middle of a critical balance sheet.
Instead, you must use markdown-aware chunking or structural element chunking. Specifically, this method parses the document visually and splits the text based on actual headers, such as “Risk Factors” or “Management Discussion.” According to Snowflake engineering data, utilizing markdown-aware chunking without global context actually boosts final answer accuracy by 5% to 10% compared to fixed-size splitting.
Additionally, you must strictly manage the exact size of your chunks. Generally, many developers assume that feeding massive chunks into long-context language models solves retrieval problems automatically. Yet, empirical data proves otherwise.
Specifically, using overly large chunks of roughly 14,400 characters bundles too much irrelevant text together, diluting the search relevance and dropping overall performance by 10% to 20%. Conversely, utilizing moderate chunk sizes of approximately 1,800 characters and retrieving the top 50 results yields the highest factual accuracy. Therefore, if you need assistance building these specific parsing pipelines, our custom AI development team specializes in complex document extraction.
Step 2 Select Financial Embedding Models and Manage Storage
Once you chunk the text correctly, you must run those segments through an embedding model. Functionally, this model converts human text into high-dimensional floating-point numbers. Standard general-purpose models, like OpenAI’s text-embedding-ada-002, work well for casual conversation but often struggle to differentiate nuanced financial terminology.
Therefore, you should evaluate domain-specific open-source models trained directly on financial corpora. Inherently, these specialized models map financial synonyms much closer together in the vector space. However, you must carefully calculate the resulting memory footprint of your vector database before moving to production.
According to research published by Cornell University, storing high-dimensional embeddings demands massive cloud memory. For instance, a knowledge base containing just one million documents embedded into 1,536-dimensional float32 vectors requires roughly 6.1 GB of RAM just for the raw vectors. As your dataset scales to tens of millions of SEC filings, your operational costs will undoubtedly skyrocket.
Consequently, you must explore dimensionality reduction or vector quantization. Essentially, quantization reduces the number of bits used to represent each numerical component, drastically lowering your server costs while maintaining acceptable retrieval accuracy. Applying proper data analytics to your infrastructure costs is ultimately just as important as the model accuracy itself.
Step 3 Apply Hybrid Retrieval and Metadata Routing
Embedding the text perfectly only solves half of the problem. When users query the system, the retrieval engine must reliably find the right needles in a massive haystack. Pure vector similarity search frequently fails in finance because companies use identical boilerplate language year after year.
To resolve this, you must implement Semantic File Routing (SFR) or Hybrid Document-Routed Retrieval (HDRR). Operationally, this two-stage architecture first uses metadata to filter down to the exact document, and only then performs a vector search within that specific file. An arXiv evaluation proved that this HDRR method absolutely eliminates cross-document confusion, pushing the perfect-answer rate to 20.1% while dropping the failure rate to a mere 6.4%.
Furthermore, you must enrich every single chunk with strict metadata before saving it to your database. Ideally, you should append the company ticker, the document year, the SEC form type, and the sector to the vector payload. A recent Stanford University report on FinRAG demonstrated that clustering data by metadata attributes significantly outperforms traditional text similarity methods.
Moreover, if your financial documents contain complex charts or scanned images, standard text extraction will fail entirely. In these specific cases, you must deploy advanced computer vision and AI image detector models to physically parse the tabular data into structured markdown before chunking begins.
Summary Table Baseline vs Advanced Financial RAG
Understanding the specific differences between a naive setup and a production-ready financial system remains critical. Therefore, review the following technical comparison to evaluate your current architecture.
| Component | Baseline Vectorization | Advanced Financial Vectorization |
| Chunking Method | Fixed token size (e.g., 512 tokens) | Markdown-aware and structural chunking (~1,800 chars) |
| Embedding Model | General purpose (e.g., ada-002) | Domain-specific or heavily fine-tuned financial models |
| Database Storage | Full float32 precision | Quantized vectors for lower cloud RAM consumption |
| Retrieval Strategy | Pure cosine similarity search | Hybrid Document-Routed Retrieval (HDRR) |
| Metadata Use | None | Strict tagging (Ticker, Year, Form Type, Sector) |
Case Study Resolving Hallucinations in Form 10-K Analysis
To illustrate these concepts practically, consider a recent deployment involving an asset management firm. Initially, the firm built an internal AI tool to summarize risks from hundreds of Form 10-K filings. During the first phase, they utilized a basic recursive chunking strategy and standard vector search.
Unfortunately, the analysts immediately rejected the tool. For example, when asked about a specific automotive company’s supply chain risks in 2024, the AI frequently cited paragraphs from a different company’s 2022 filing. Because the semantic meaning of “supply chain disruption” looks mathematically identical across different vectors, the system retrieved the wrong data entirely.
To fix this catastrophic failure, the engineering team completely overhauled the data ingestion pipeline using advanced NLP techniques. First, they implemented markdown-aware chunking to preserve the boundaries of the “Risk Factors” sections. Second, they enforced strict metadata tagging on every resulting chunk.
Subsequently, they modified the retrieval query to enforce a hard metadata filter based on the user’s prompt. Thus, if the user asked about 2024, the vector database ignored all vectors lacking the “Year: 2024” tag. Ultimately, this structural routing eliminated cross-document hallucinations entirely, allowing the firm to confidently deploy the tool to their entire trading floor.
3 Actionable Steps You Can Take Today
- Audit your current chunking strategy immediately. You must ensure you are not slicing documents arbitrarily, and you should aim for structural boundaries that average roughly 1,800 characters per chunk.
- Implement metadata filtering in your vector database right now. Before running a similarity search, force your application to filter out irrelevant years, sectors, and companies using strict key-value tags.
- Calculate your projected vector storage costs. If you plan to scale past one million financial documents, you must test vector quantization methods to prevent cloud memory expenses from ruining your project budget.
Conclusion
Building a highly accurate financial RAG system requires precise engineering, rigorous data preparation, and a deep understanding of structural text parsing. By implementing intelligent chunking and hybrid retrieval routing, you can completely eliminate the hallucinations that plague basic AI tools. If you need custom help implementing this exact architecture into your production environment, our AI consulting and strategy agency can assist. You can reach out directly at https://tensour.com/contact to start building efficient, purpose-driven solutions.
Leave a Reply