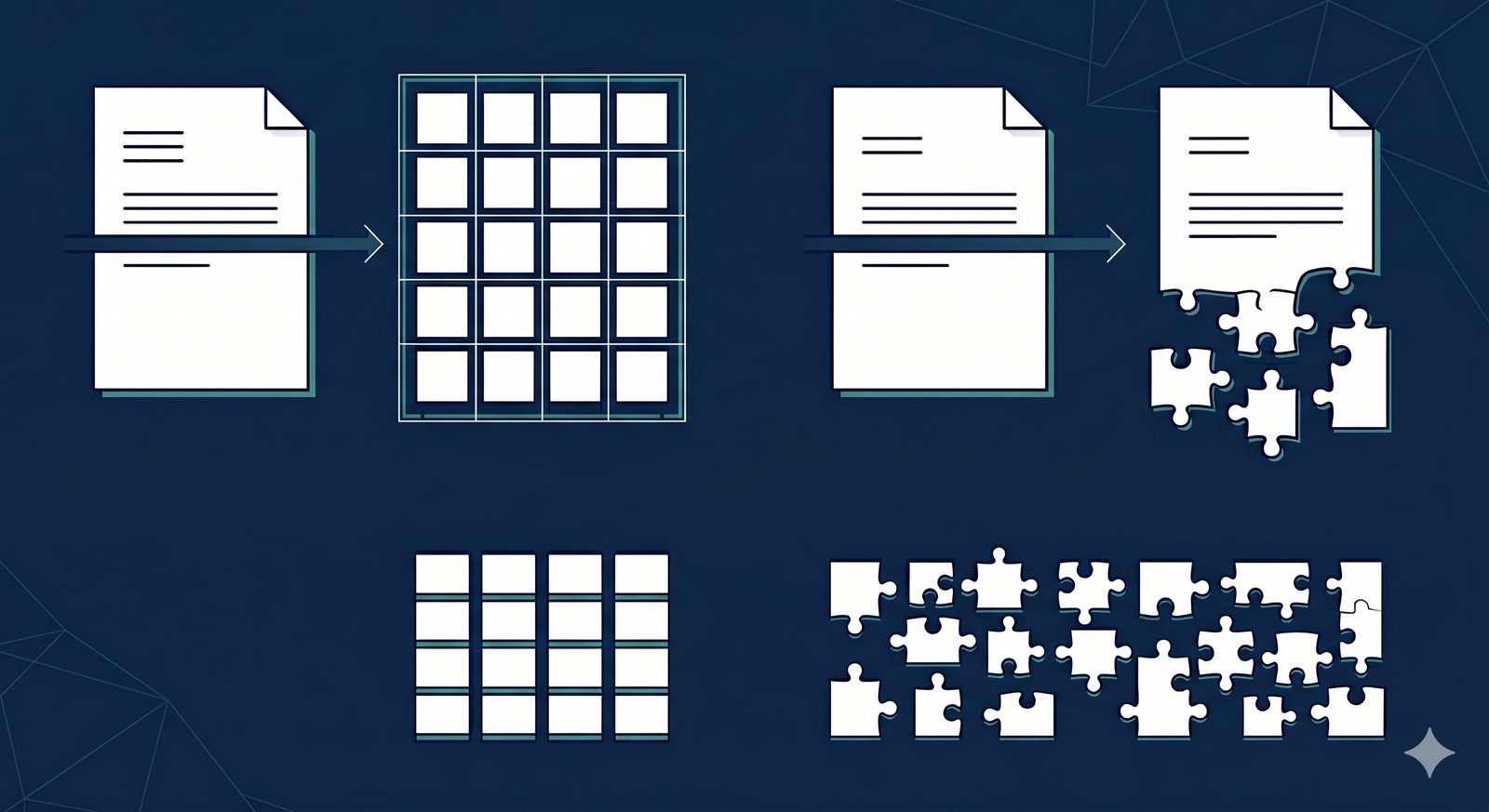
The Core Difference Between Chunking Strategies
Fixed-size chunking divides text into equal segments based on a strict token limit, while semantic chunking uses machine learning to split text at natural, context-rich boundaries like topic changes. Although semantic chunking preserves meaning better and prevents awkward mid-sentence splits, recent data shows that fixed-size chunking with a 10-20% overlap often delivers equal or superior retrieval accuracy at a fraction of the computational cost. The best chunking strategy for RAG implementation depends entirely on your document structure, budget, and latency requirements.
Why Chunking Dictates RAG Performance
In Retrieval-Augmented Generation (RAG), Large Language Models (LLMs) rely on a vector database to fetch relevant context before answering a user’s prompt. If you feed the database poorly cut pieces of text, the model retrieves fragmented or irrelevant information. This phenomenon leads to hallucinations and poor answer generation.
Chunking is the bridge between raw documents and your vector database. The debate in the data science community right now is whether to use a fast, naive approach or a slow, intelligent approach to cut up these documents. Marketing material often pushes the intelligent approach, but engineering reality is much more nuanced.
Fixed-Size Chunking: The Industry Standard
Fixed-size chunking, also known as fixed-character or token-based chunking, is the most common method used in production environments today. It is entirely indifferent to what the text actually says. You set a hard limit—for example, 512 tokens—and the algorithm simply slices the document every time it hits that number.
To prevent cutting a crucial sentence in half, engineers add an “overlap” parameter. An overlap of 10% to 20% ensures that the end of one chunk is repeated at the beginning of the next, maintaining a thin thread of context.
The Fixed-Size Implementation Process
- Establish your token limit based on your embedding model’s capacity (e.g., OpenAI’s text-embedding-3-small handles 8191 tokens, but 256 to 512 is typical for retrieval).
- Set a token overlap constraint, usually between 50 and 100 tokens.
- Parse the raw document string sequentially.
- Slice the string at the exact token limit, carrying the overlap over to the start of the next slice.
- Pass the uniform slices to the embedding model for vectorization.
The primary advantage here is predictability. You know exactly how much memory you will consume, and the process requires zero natural language processing overhead. The major downside is semantic fragmentation. A numbered list or a complex policy exception might be split across two separate chunks, making it difficult for the retriever to grab the complete thought.
Semantic Chunking: The Context-Aware Alternative
Semantic chunking attempts to solve the fragmentation problem by analyzing the meaning of the text before cutting it. Instead of blindly counting tokens, it looks for natural breakpoints—like a shift from talking about “installation” to “troubleshooting.”
This method ensures that every chunk stored in your vector database is a cohesive, self-contained thought.
The Semantic Chunking Process
- Split the initial text into very small, manageable units, such as individual sentences or 50-token micro-chunks.
- Pass every single micro-chunk through an embedding model to generate a vector representation of its meaning.
- Calculate the cosine similarity between adjacent vectors to measure how closely related they are in context.
- Group adjacent sentences together into a single chunk as long as their similarity score remains above a specific threshold.
- Enforce a maximum size limit to ensure the final chunk does not exceed the LLM’s context window.
While semantic chunking sounds superior on paper, it requires an intensive double-embedding pass. You must embed the text just to figure out where to cut it, and then you often embed the final chunks again for storage. If you are using a paid API, this significantly increases your document processing costs.
Is Semantic Chunking Worth the Computational Cost?
There is a widespread assumption that semantic chunking inherently leads to better RAG accuracy. However, rigorous testing tells a different story.
A comprehensive October 2024 study published on arXiv titled Is Semantic Chunking Worth the Computational Cost? systematically evaluated chunking strategies across multiple RAG tasks. The researchers measured performance using the F1@5 metric, which balances precision and recall.
The data revealed that semantic chunking failed to show a clear advantage in identifying evidence sentences across unmodified datasets. In fact, for standard document retrieval tasks, fixed-size chunking consistently outperformed semantic chunking. The researchers concluded that the advantages of semantic chunking are highly task-dependent and often insufficient to justify the added computational overhead.
Similarly, independent tests reported by platforms like Vectara and community developers on Reddit validate this. Smaller fixed chunks (e.g., 256 tokens) with a modest overlap (e.g., 64 tokens) consistently yield higher precision than complex semantic boundaries. Semantic chunking can offer slight recall improvements in hybrid retrieval setups, but it is not the magic bullet marketing claims it to be.
Chunking Strategy Comparison Table
| Feature | Fixed-Size Chunking | Semantic Chunking |
| Core Logic | Token or character count | Meaning and context shifts |
| Processing Speed | Extremely fast | Slow (Requires pre-embedding) |
| API Costs | Low (Single embedding pass) | High (Multiple embedding passes) |
| Best Document Type | Uniform, short FAQs, logs | Narrative reports, complex research |
| Retrieval Accuracy | High precision (with overlap) | Better context boundaries |
| Implementation Difficulty | Very simple | Complex (Threshold tuning needed) |
Case Study: Optimizing an Enterprise Knowledge Base
Consider an enterprise client who built an internal RAG system to query 10,000 pages of compliance documentation. Initially, they utilized semantic chunking via LangChain, assuming it would provide the most accurate answers for complex legal text.
However, their ingestion pipeline was bottlenecked. Processing new document uploads took hours, and OpenAI API costs were ballooning due to the initial semantic similarity checks. Furthermore, users complained that the retriever was pulling massive, multi-paragraph chunks that diluted the specific answers they needed.
The engineering team switched to a fixed-size chunking strategy of 384 tokens with a 96-token overlap. They also implemented a cross-encoder reranker to handle relevance scoring after the initial retrieval.
The results were measurable. Ingestion speed increased by 400%, API costs dropped by nearly 50%, and end-user feedback indicated that the responses were actually more precise. The reranker effortlessly compensated for the arbitrary chunk boundaries, proving that investing compute power at the retrieval stage (reranking) is often more effective than investing it at the ingestion stage (semantic chunking).
3 Actionable Steps to Optimize Your RAG Chunking Today
- Implement a Parent-Child Document Architecture. Instead of choosing between small and large chunks, use both. Index small, fixed-size chunks (256 tokens) for highly precise similarity search, but return the larger parent document (1000+ tokens) to the LLM to provide full context.
- Dial in Your Overlap Threshold. If you are using fixed-size chunking, do not skip the overlap. Ensure your overlap is exactly 10% to 20% of your total chunk size. This single parameter change often resolves the “lost context” issue that pushes developers toward semantic chunking.
- Add a Reranker to Your Pipeline. Rather than spending API credits on complex semantic chunking during document ingestion, use a simple fixed-size strategy and pass the retrieved results through a reranker (like Cohere or BGE). Reranking quietly fixes the mess of arbitrary chunk boundaries and drastically improves precision.
Need Help Scaling Your AI Infrastructure?
Navigating the nuances of document processing, embedding models, and vector search requires deep engineering expertise. If you need custom help implementing optimized RAG architectures or scaling your data pipelines without exploding your API costs, our AI & Data Science agency can assist you. Reach out to us at https://tensour.com/contact to discuss your specific infrastructure needs.
Leave a Reply